图神经网络学习笔记
图(Graphs)
简介
图是一种普遍存在的数据结构,也是描述复杂系统的通用语言。从最普遍的角度来看,图仅仅是对象(即节点)以及这些对象对之间一组交互(即边)的集合。例如,为了将社交网络编码为图,我们可以使用节点来表示个体,使用边来表示两个人是朋友。在生物学领域,我们可以用图中的节点来表示蛋白质,用边来表示各种生物相互作用,例如蛋白质之间的动力学相互作用。
从数学角度,图可以由表征,由一组节点和这些节点之间的一组边定义。一般将从节点到的边表示为。在很多情况下,我们只关注简单的图,其中每对节点之间最多有一条边,节点与其自身之间没有边,并且所有边都是无向的。
在数学角度,表示图的便捷方法是使用邻接矩阵。为了用邻接矩阵表示图,我们对图中的节点进行排序,使得每个节点都索引邻接矩阵中的特定行和列。然后,我们可以将边的存在表示为该矩阵中的元素:如果 ,则 ,否则 。如果图仅包含无向边,则 A 将是对称矩阵;但如果图是有向的(即边的方向很重要),则 A 不一定是对称的。某些图还可以包含加权边,其中邻接矩阵中的元素是任意实值,而不是 。
异构图:在异构图中,节点也具有类型(节点可以继续细分),这意味着我们可以将节点集划分为不相交的集合,其中 ,其中 。异构图中的边通常根据节点类型满足约束,最常见的约束是某些边仅连接特定类型的节点,即 。例如,在异构生物医学图中,可能有一种类型的节点代表蛋白质,一种类型的节点代表药物,还有一种类型的节点代表疾病。表示“治疗”的边只会出现在药物节点和疾病节点之间。类似地,表示“多种药物副作用”的边只会出现在两个药物节点之间。
多重图:在多重图中,我们假设图可以分解为一组$ k $层。假设每个节点属于每个层,并且每个层对应一个唯一的关系,表示该层的层内边类型。我们还假设可以存在跨层连接同一节点的层间边类型。通过示例可以更好地理解多重图。例如,在多重交通网络中,每个节点可能代表一个城市,每个层可能代表一种不同的交通方式(例如,航空旅行或火车旅行)。层内边表示由不同交通方式连接的城市,而层间边表示在特定城市内切换交通方式的可能性。
图和机器学习
节点分类
图的一个经典应用是根据少量标注,来从一批互联网用户中提取出bot账号。乍一看,节点分类似乎是标准监督分类的简单变体,但实际上它们之间存在重要区别。最重要的区别在于,图中的节点并非独立同分布 (i.i.d.)。
通常,在构建监督机器学习模型时,我们假设每个数据点在统计上与所有其他数据点独立;否则,我们可能需要对所有输入点之间的依赖关系进行建模。我们还假设数据点是同分布的;否则,我们无法保证我们的模型能够推广到新的数据点。
节点分类完全打破了这一独立同分布假设。我们不是对一组独立同分布的数据点进行建模,而是对一组相互连接的节点进行建模。这种建模方式非常关注节点之间的依赖关系,期望明确的利用节点之间的连接。
关系预测
节点分类有助于根据节点与图中其他节点的关系推断其相关信息。但是,如果我们缺少这种关系信息,该怎么办呢?如果我们只知道特定细胞中存在的部分蛋白质相互作用,但想对缺失的相互作用做出准确的猜测,该怎么办?我们可以使用机器学习来推断图中节点之间的边吗?
这项任务有很多名称,例如链接预测、图补全和关系推断,具体取决于具体的应用领域。我们在这里简称为关系预测。与节点分类一样,它是图数据中最流行的机器学习任务之一,并且在现实世界中有着无数的应用。
关系预测的标准场景是,给定一组节点以及这些节点之间的不完整的边集,利用这部分信息推断出缺失的边。这项任务的复杂性在很大程度上取决于我们正在研究的图数据的类型。与节点分类类似,关系预测模糊了传统机器学习类别(通常被称为监督式和无监督式)的界限,并且它需要特定于图领域的归纳偏差。此外,与节点分类类似,关系预测也存在多种变体。
分类,回归和聚类
试图学习图数据,但不是对单个图的各个组成部分(即节点或边)进行预测,而是给定一个包含多个不同图的数据集,我们的目标是针对每个图进行独立的预测。
- 类似于:通过学习多个工况下的数据,对每个工况下进行独立的预测
最关键的挑战:如何定义有用的特征,以考虑到每个数据点内的关系结构。
背景和传统方法
图数据和核方法(Kernel Methods)
图中有几个比较重要的要素:
-
节点度(Node degree):和节点关联的边(edge)的个数。通常是应用于节点级任务的传统机器学习模型中最具信息量的特征之一。
-
节点中心性(Node centrality):度只是衡量每个节点有多少个邻居,而特征向量中心性还考虑了节点邻居的重要性。
节点的特征向量中心性e_u通常用一个递归关系来定义,即节点的中心性与其邻居节点的平均中心性成正比:
将该方程改写为向量的形式,以作为描述节点中心性的向量,这个递归关系定义了邻接矩阵的标准特征向量方程:
根据定理,中心度值向量 由 中最大特征值对应的特征向量给出。
预印本第12页对表征节点中心性的不同指标做了综述。
- 聚类系数(Clustering coefficient)
节点度和节点中心度可能不足以区分开图中其他节点的特征,比如两个节点度和中心度都很相似的节点,可能也存在明显的差异。
这种结构区别可以用聚类系数的变体来衡量,其是节点局部邻域中闭合三角形的比例。聚类系数的常用局部变体计算见13页
- 封闭的三角形和主题(closed triangles and motifs)
另一种看待聚类系数的方式是计算每个节点局部邻域内闭合三角形的数量
图级特征和图核(Graph-level features and graph kernels)
暂不讨论
邻域重叠检测(Neighborhood Overlap Detection)
暂不讨论,电力系统中边的存在都是确定的
节点嵌入(Node embeddings)
领域重构方法(Neighborhood Reconstruction methods)
这一部分关注的是学习节点嵌入的方法。这些方法的目标是将节点编码为低维向量,这些向量概括了它们在图中的位置及其局部图邻域的结构。换句话说,我们希望将节点投影到一个潜在空间中,其中,该潜在空间中的几何关系对应于原始图或网络中的关系.
编码器-解码器视角(An Encoder-Decoder Perspective)
涉及两个关键操作:
- 编码器模型将图中的每个节点映射到一个低维向量
- 解码器模型获取低维节点嵌入,重建为原始图中每个节点邻域的信息。第30页
编码器(Encoder)
最简单的浅嵌入编码器:
解码器(Decoder)
优化编码器-解码器模型
为实现重建目标,标准做法是最小化一组训练节点对的经验重建损失:
是一个损失函数,用于衡量解码后的相似度值和真实值之间的差异,可能是均方误差或交叉熵等。大多数方法使用随机梯度下降来最小化损失。
编码器-解码器方法概述
著名的浅层嵌入方法包括:
- Lap. Eigenmaps
- Graph Fact.
- GraRep
- HOPE
- DeepWalk
- node2vec
所有这些方法都使用了浅层编码方法。编码器-解码器框架的主要优势在于,可以基于
- 解码器函数
- 基于图的相似度度量
- 损失函数
来简洁地定义和比较不同的嵌入方法
基于矩阵分解的方法(Factorization-based approaches)
拉普拉斯矩阵的定义:
是度矩阵,表示了每个节点的节点度;是邻接矩阵,表示了连接关系
从节点嵌入中解码局部邻域结构的挑战与重建图邻接矩阵中的条目密切相关。更一般地,我们可以将此任务视为使用矩阵分解来学习节点-节点相似性矩阵 S 的低维近似。
- 拉普拉斯特征图(Laplacian eigenmaps):最早也是最具影响力的基于因式分解的方法,根据节点嵌入的L2距离来定义解码器:
然后,损失函数根据图中的相似度对节点对进行加权:
这种方法非常直白,当应当非常相似的节点之间的嵌入过远时,损失函数会对没模型进行惩罚。假设嵌入是维的,那么损失函数的最优解应当由拉普拉斯矩阵的个最小特征向量给出。
- 内积法(Inner Product Methods):部分编码器采用内积方法:
此处假设两个节点之间的相似度和他们嵌入的点积成正比。Graph Factorization、GraRep和HOPE均使用内积编码器。这三种方法都将内积编码器和以下均方误差相结合:
三种方法的主要区别在于如何定义式中的,即如何定义他们所使用的节点间相似性或邻域重叠的概念:
- GF方法直接使用邻接矩阵并设置和
- GraRep基于邻接矩阵的幂定义
- HOPE支持通用的邻域重叠度量
以上的方法都被称为矩阵分解方法,因为他们的损失函数都可以使用分解算法(如奇异值分解SVD)最小化。直观地说,这些方法的目标是为每个节点学习嵌入,使得学习到的嵌入向量之间的内积近似于节点相似度的某个确定性度量。
随机游走嵌入(Random walk embeddings)
内积方法都采用了节点相似度的确定性度量,即将定义为邻接矩阵的某个多项式函数,并对节点嵌入进行优化,使得。
随机游走嵌入方法将内积方法应用于邻域重叠的随机度量,创新之处在于对节点嵌入进行优化,使得如果两个节点倾向于在图上的短随机游走中同时出现,则二者具有相似的嵌入。
- DeepWalk & node2vec:这两种方法和上述的矩阵分解方法类似,都使用了浅嵌入方法和内积解码器,关键区别在于他们如何定义节点相似性和邻域重构的概念,这些方法并非直接重构邻接矩阵(或的某个确定性函数),而是优化嵌入以编码随机游动的统计数据。
从数学上讲,目标是学习嵌入,使以下公式得到大致满足:
其中是从触发,在长度为的随机游动中访问的概率,通常定义为2到10的范围。这个式子和上一小节中基于分解的函数的关键区别在于,这个式子的相似性度量既是随机的,又是非对称的。
为了训练随机游走嵌入,一般策略是使用上式的解码器,并最小化以下交叉熵损失:
这里用表示随机游动的训练集,由从每个节点开始的随机游动采样生成。
- LINE
图神经网络(Graph Neural Network)
GNN是一个用于定义基于图数据的深度神经网络的通用框架,核心思想是,我们希望生成实际上依赖于图结构以及我们可能拥有的任何特征信息的节点表示。
开发用于图结构数据的复杂编码器的主要挑战在于,常用的深度学习Kit并不适用,比如CNN仅在Grid结构输入表现良好,RNN仅在序列上表现良好等。
神经信息传递
GNN的定义性特征在于其使用一种神经信息传递的形式,其中向量信息在节点间交换,并使用神经网络进行更新。
概览
在GNN的每次消息传递迭代中,每个节点对应的隐藏嵌入会根据从u的邻居聚合的信息进行更新。
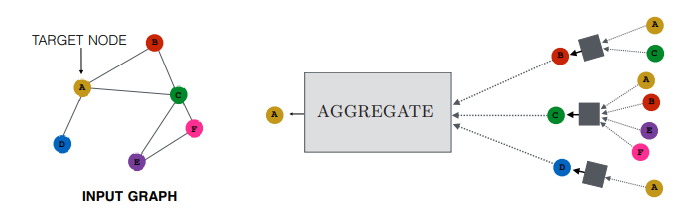
节点特征:与本书第一部分讨论的浅嵌入方法不同,GNN 框架要求我们将节点特征,
作为模型的输入。在许多图中,我们会有丰富的节点特征可供使用(例如,生物网络中的基因表达特征或社交网络中的文本特征)。但是,在没有节点特征可用的情况下,仍然有几种选择。一种选择是使用节点统计数据(例如 2.1 节中介绍的统计数据)来定义特征。另一种流行的方法是使用身份特征,我们将每个节点与一个独热指示器特征相关联,该特征唯一地标识该节点。
动机和直觉
GNN消息传递框架后的基本直觉很简单:在每次迭代中,每个节点都会聚合来自其本地邻域的信息,并且随着迭代的进行,每个节点嵌入都会包含越来越多的来自图更远范围的信息。次迭代之后,每个节点嵌入都包含其范围邻域的信息。
问题是,这些节点嵌入实际上编码了什么样的信息。通常这种信息有两种形式:
-
图的结构信息:次迭代后节点的嵌入可能编码了的跳邻域内所有节点的节点度信息,这种信息在许多任务中都很有用,比如分子图。
-
节点特征信息:次迭代后每个节点的嵌入还编码了其跳邻域内所有特征的信息,GNN的局部特征聚合行为类似于CNN中卷积核的行为。不同的是,CNN聚合的是图像中空间定义块的特征信息,而GNN基于局部图邻域聚合信息。
基本GNN
基本的GNN消息传递可被定义为:
其中和为可训练参数矩阵,表示元素非线性(如tanh和ReLU)。为偏置项,通常被忽略,但是对于实现高性能非常重要。
基本GNN框架中的消息的传递类似于MLP或Elman RNN,因为他依赖于线性运算,然后进行单元素非线性运算:
- 对来自邻居节点的消息进行求和
- 使用线性组合将邻居节点的信息与节点之前的嵌入进行组合
- 应用元素非线性运算
带有自循环的消息传递
为了简化神经消息传递方法,通常会在输入图中添加自循环,并省略显式更新步骤。在这种方法中,我们将消息传递简单定义为:
这样做令聚合操作针对的是节点的邻居和节点本身,不再需要定义显式的更新函数,因为更新是通过聚合方法隐式定义的。这种方式可缓解过拟合,但也严重限制了GNN的表达能力,因为来自节点邻居的信息与来自节点本身的信息无法区分。
广义邻域聚合(Generalized Neighborhood Aggregation)
基本GNN同MLP一样,可以通过多种方式进行改进和泛化以达到更好的性能。
邻域归一化
最基本的邻域聚合只是简单的对邻居嵌入求和,这样的一个问题是它可能不稳定,并且对节点高度敏感。
解决这一问题的一个方法是简单的根据所涉及节点的度对聚合操作进行归一化,比如取平均值:
研究表明其他归一化方法也可以达到很好的性能:
例如,被引用太多次的论文可能对于推断图中的社区成员身份没有太大用处,因为这些论文可能在不同的子领域内被引用数千次(电力系统中的发电机也是这个道理)。
是否要进行归一化?:
在使用 GNN 时,适当的归一化对于实现稳定且强大的性能至关重要。然而,需要注意的是,归一化也可能导致信息丢失。例如,归一化后,使用学习到的嵌入来区分不同度数的节点可能变得困难(甚至不可能),并且各种其他结构图特征可能会因归一化而变得模糊。因此,归一化的使用是一个特定于应用的问题。通常,在节点特征信息远比结构信息更有用,或者节点度数范围非常广,可能导致优化过程中不稳定的任务中,归一化最有帮助。
图卷积网络(GCN)
图卷积网络 (GCN)采用了对称归一化聚合以及自循环更新方法。GCN 模型将消息传递函数定义为:
Set Aggregators
邻域归一化可以成为提升 GNN 性能的有效工具,但我们能否做更多来改进 AGGREGATE 运算符?是否有比仅仅对邻域嵌入求和更复杂的方法?
邻域聚合运算本质上是一个集合函数。给定一组邻域嵌入,我们必须将这个集合映射到一个向量。
边(Edge)特征和多关系图神经网络(GNN)
在许多应用中,所涉及的图是多关系的或异构的(例如知识图谱)。
GNN的实践
应用的损失函数
在当前的绝大多数应用中,GNN 用于以下三个任务之一:节点分类、图分类或关系预测。如第一章所述,这些任务反映了大量的实际应用,例如预测用户在社交网络中是否为机器人(节点分类)、基于分子图结构的属性预测(图分类)以及在线平台中的内容推荐(关系预测)。
在本节中,我们将简要描述如何将这些任务转化为 GNN 的具体损失函数,并讨论如何以无监督的方式对 GNN 进行预训练,以提高这些下游任务的性能。
我们将使用表示GNN最后一层的节点嵌入输出,并使用表示池化函数输出的图级嵌入.
节点分类
GNN应用于此类节点分类任务的标准方法是采用全监督方式训练GNN,并使用Softmax分类函数和负对数似然损失来定义损失:
假设是一个独热向量,表示训练节点的类别。
这种策略是以训练GNN的最常见的优化策略之一。
监督,半监督,传导和归纳式:
节点分类设置通常被称为监督式和半监督式。应用这些术语时,一个重要因素是,在训练 GNN 期间是否以及如何使用不同的节点。通常,我们可以区分三种类型的节点:
- 训练节点集 Vtrain。这些节点包含在 GNN 消息传递操作中,并且它们也用于计算损失,
- 除了训练节点之外,我们还可以有传导式测试节点 Vtrans。这些节点未标记,不用于损失计算,但这些节点及其关联边仍然参与 GNN 消息传递操作。换句话说,GNN 将在 GNN 消息传递操作期间为 u ∈ Vtrans 中的节点生成隐藏表示。然而,这些节点的最终层嵌入 zu 将不会用于损失函数计算。
- 最后,我们还将有归纳测试节点 Vind。这些节点在训练期间既不会用于损失计算,也不会用于 GNN 消息传递操作,这意味着这些节点及其所有边在 GNN 训练期间完全不可见。
“半监督”一词适用于在直推测试节点上测试 GNN 的情况,因为在这种情况下,GNN 在训练期间会观察测试节点(但不观察它们的标签)。“归纳节点分类”一词用于区分测试节点及其所有关联边在训练期间完全不可见的情况。归纳节点分类的一个例子是在引文网络的一个子图上训练 GNN,然后在一个完全不相交的子图上对其进行测试。
图分类
与节点分类类似,图级分类应用作为基准测试任务也很受欢迎。历史上,核方法(Kernel Methods)在图分类中很流行,因此,一些早期最流行的图分类基准测试都改编自核方法文献。在这些任务中,通常使用softmax 分类损失。近年来,图神经网络 (GNN) 在涉及图数据的回归任务中也取得了成功,尤其是在基于图的分子表示预测分子特性(例如溶解度)的任务中。