串口(uart)是一种低速的串行异步通信,适用于低速通信场景,通常使用的波特率小于或等于115200bps。
对于小于或者等于115200bps波特率的,而且数据量不大的通信场景,一般没必要使用DMA,或者说使用DMA并未能充分发挥出DMA的作用。
对于数量大,或者波特率提高时,必须使用DMA以释放CPU资源,因为高波特率可能带来这样的问题:
对于发送,使用循环发送,可能阻塞线程,需要消耗大量CPU资源“搬运”数据,浪费CPU
对于发送,使用中断发送,不会阻塞线程,但需浪费大量中断资源,CPU频繁响应中断;以115200bps波特率,1s传输11520字节,大约69us需响应一次中断,如波特率再提高,将消耗更多CPU资源
对于接收,如仍采用传统的中断模式接收,同样会因为频繁中断导致消耗大量CPU资源
使用HAL_UARTEx_ReceiveToIdle_IT函数,该函数会持续接收数据,直到缓冲区溢出或触发空闲事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 if (huart->RxState == HAL_UART_STATE_READY)if ((pData == NULL) || (Size == 0 U))return HAL_ERROR;if (status == HAL_OK)if (huart->ReceptionType == HAL_UART_RECEPTION_TOIDLE)else return status;else return HAL_BUSY;
1 2 3 4 /* USER CODE BEGIN 2 */USER CODE END 2 */
每次接收完数据(指溢出或空闲后)进入该回调,将缓冲区数据传回上位机,然后重新准备下一次接收
1 2 3 4 5 6 7 8 9 HAL_UARTEx_RxEventCallback (UART_HandleTypeDef *huart, uint16_t Size)HAL_UART_Transmit_IT (&huart1, (uint8_t *)RxBuffer, sizeof (RxBuffer));HAL_UARTEx_ReceiveToIdle_IT (&huart1, (uint8_t *)RxBuffer, RX_BUFFER_SIZE);
DMA绕过CPU进行数据传输(外设-内存),因此可以节省CPU资源。DMA分为正常(Normal)模式和循环(Circular)模式,一般大规模数据传输时使用循环模式。 HAL_UARTEx_ReceiveToIdle_DMA函数,仅需在最开始调用一次。当接收完成(达到指定字节数)或触发Idle事件时接收停止。每次接收事件完成后触发HAL_UARTEx_RxEventCallback中断回调。
应用要求:输入一段文字,若MCU成功接收则回复“Wilco”。
在loop前调用一次以启动接收:
1 HAL_UARTEx_ReceiveToIdle_DMA(&huart1 , (uint8_t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int count = 0 ; uint16_t index = 0 ; uint8_t Wilco[] = "wilco\n" ; void HAL_UARTEx_RxEventCallback (UART_HandleTypeDef *huart, uint16_t Size) HAL_UART_Transmit_IT (&huart1, (uint8_t *)Wilco, sizeof (Wilco)); HAL_UARTEx_ReceiveToIdle_DMA (&huart1, (uint8_t *)RxBuffer, RX_BUFFER_SIZE);
参考文献 :
一个严谨的STM32串口DMA发送&接收(1.5Mbps波特率)机制
STM32 HAL 库实现乒乓缓存加空闲中断的串口 DMA 收发机制,轻松跑上 2M 波特率
MaJerla(Github)
DMA在循环模式下工作时,如果在大规模传输数据时仍旧空闲中断(或传输完成中断)会有风险,因为当DMA传输数据完成,CPU介入开始拷贝DMA通道缓冲区数据时,如果此时UART继续有数据进来,DMA继续搬运数据到缓冲区,就有可能将数据覆盖,因为DMA数据搬运是不受CPU控制的,即使你关闭了CPU中断。
因此严谨的做法需要建立双buffer,CPU和DMA各自使用一块内存交替访问,即乒乓缓存 ,处理流程为:
DMA先将数据搬运到buf1,搬运完成通知CPU来拷贝buf1数据
DMA将数据搬运到buf2,与CPU拷贝buf1数据不会冲突
buf2数据搬运完成,通知CPU来拷贝buf2数据
DMA继续开始拷贝新数据
STM32大多数型号不提供现成的双缓存机制,但提供“半满中断”,即数据搬运到buf大小的一半时,可以产生一个中断信号。基于这个机制,我们可以实现双缓存功能,只需将buf空间开辟大一点即可。
DMA将数据搬运完成buf的前一半时,触发“半满中断”事件,Callback中通知CPU来拷贝buf前半部分数据
DMA继续将数据搬运到buf的后半部分,与CPU拷贝buf前半部数据不会冲突
buf后半部分数据搬运完成,触发“溢满中断”,Callback通知CPU来拷贝buf后半部分数据
DMA循环拷贝新数据
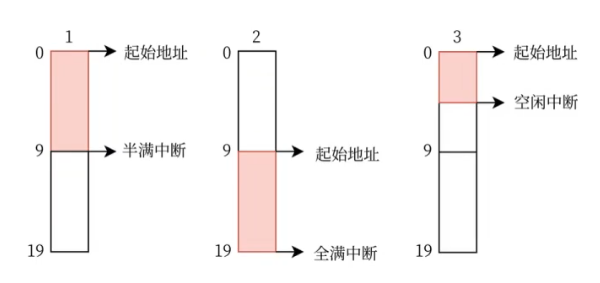
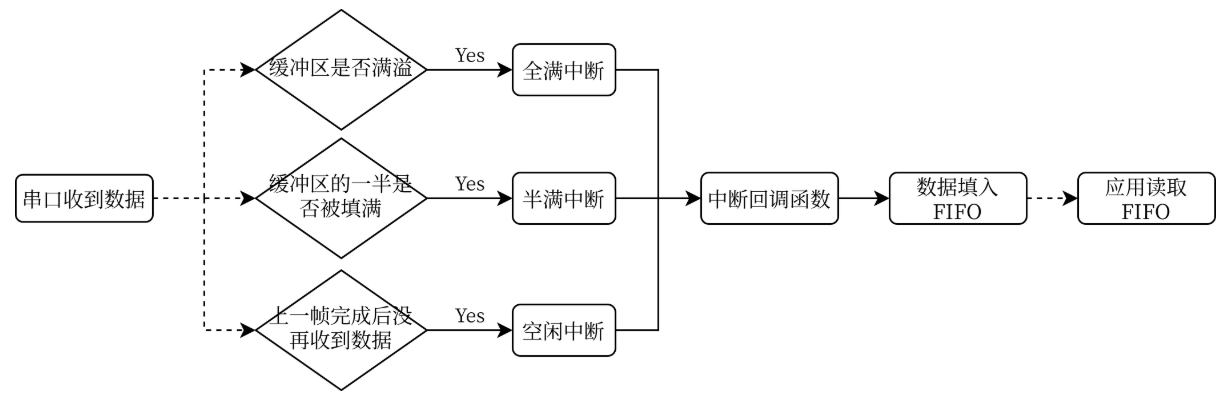
基于上述描述机制,DMA方式接收串口数据,有三种中断场景需要CPU去将buf数据拷贝到final中,分别是:
DMA通道buf溢满(传输完成)场景,触发满溢中断(HAL_UARTEx_RxEventCallback)
DMA通道buf半满场景,触发半满中断(HAL_UART_RxHalfCpltCallback)
串口空闲中断场景,触发空闲中断(UART_FLAG_IDLE)
也就是说,代码总共需要考虑以下几种情况:
数据量未达到半满,触发空闲中断
数据量达到半满,未达到满溢,先触发半满中断 ,后触发空闲中断
数据量刚好达到满溢,先触发半满中断 ,后触发满溢中断
数据量大于缓冲区长度,DMA循环覆盖溢出的字节
对于情况1:在空闲中断中拷贝全部数据
对于情况2:在半满中断中通知CPU拷贝一半的数据,DMA继续接收剩下的数据,最后在空闲中断中拷贝剩下的数据
对于情况3:在半满中断中通知CPU拷贝一半的数据,DMA继续接收剩下的数据,最后在满溢中断中拷贝剩下的一半数据
对于情况4:综合处理
下面这个代码经过试验不太好使,空闲中断和满溢中断似乎有冲突,导致接收完成后MCU进不去满溢中断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 if (__HAL_UART_GET_FLAG (&huart1 , UART_FLAG_IDLE))LAG (&huart1 , UART_FLAG_IDLE);&huart1 );&hdma_usart1_rx ); //已接收的数据大小if (temp != 0)"rx ok in idle IT\n" ;&huart1 , txbuffer, sizeof(txbuffer), 0xFFFF);if (rx_half_flag == 0)&huart1 , Rx_buffer, RX_BUFFER_SIZE - temp);else if (rx_half_flag)&hdma_usart1_rx ) - RX_BUFFER_SIZE / 2;&huart1 , Rx_buffer, RX_BUFFER_SIZE/2 - temp_size);else if (temp == RX_BUFFER_SIZE)&huart1 , Rx_buffer, RX_BUFFER_SIZE);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void HAL_UART_RxHalfCpltCallback (UART_HandleTypeDef *huart) if (huart->Instance == USART1)1 ;uint8_t sendbuffer[] = "rxhalf IT\n" ;HAL_UART_Transmit (&huart1, (uint8_t *)sendbuffer, sizeof (sendbuffer), 0xFFFF );for (int i = 0 ; i < RX_BUFFER_SIZE / 2 ; i++)HAL_UART_Receive_DMA (&huart1, (uint8_t *) Rx_buffer, RX_BUFFER_SIZE / 2 );void HAL_UARTEx_RxEventCallback (UART_HandleTypeDef *huart, uint16_t Size) if (huart->Instance == USART1)uint8_t sendbuffer[] = "rx ok\n" ;HAL_UART_Transmit (&huart1, (uint8_t *)sendbuffer, sizeof (sendbuffer), 0xFFFF );for (int i = RX_BUFFER_SIZE / 2 ; i < RX_BUFFER_SIZE; i++)0 ;HAL_UART_Receive_DMA (&huart1, (uint8_t *) Rx_buffer, RX_BUFFER_SIZE);
继续调试,删掉除打印测试信息以外的所有功能性代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 if (__HAL_UART_GET_FLAG (&huart1 , UART_FLAG_IDLE))LAG (&huart1 );&huart1 );&hdma_usart1_rx ); //已接收数据长度if (temp_size != 0)"rxidle\n" ;&huart1 , txbuf3, sizeof(txbuf3), 0xFFFF);&huart1 , txbuf1, sizeof(txbuf1), 0xFFFF);&huart1 , txbuf2, sizeof(txbuf2), 0xFFFF);
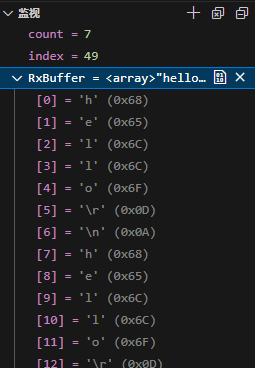
正常情况下,接收缓冲区大小为10,当发送“12”(实际为"12\r\n“四个字节)时,应只触发空闲中断;发送“123”时,触发半满中断和空闲中断;发送“12345678”时,触发半满中断和满溢中断。但测试发现,发送“12345678”共计十个字节数据,也就是预期接收数据大小等于缓冲区大小时,只能触发一次半满中断,满溢中断无法触发。若禁用空闲中断,发送“12345678”时,半满中断和溢满中断都能触发,初步判断是空闲中断的问题。
由于DMA配置在循环模式,当接收数据大小等于缓冲区大小时,RX总线仍会处于空闲状态,因为即将到来的新的数据会覆盖掉环形队列的第一项,因此实际上NVIC会先触发空闲中断,而空闲中断中有这一段代码:
1 2 3 4 5 6 7 temp_size = RX_BUFFER_SIZE - __HAL_DMA_GET_COUNTER( &hdma_usart1_rx); ( temp_size != 0 ) = "rxidle\n" ; ( &huart1, txbuf3, sizeof(txbuf3), 0xFFFF);
当接收数据大小等于缓冲区大小时,temp_size实际上等于0,导致程序在空闲中断中直接跳过了满溢判断,开始下一次接收。因此需要单独对temp_size == 0这种情况进行处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if (__HAL_UART_GET_FLAG (&huart1 , UART_FLAG_IDLE))&hdma_usart1_rx ); LAG (&huart1 );if (temp_size == 0) //满溢else if (temp_size != 0) //非满溢&huart1 );"rxidle\n" ;&huart1 , txbuf3, sizeof(txbuf3), 0xFFFF);&huart1 , Rx_buffer, RX_BUFFER_SIZE);
这样,空闲中断在数据填满缓冲区时不会进行任何操作而直接跳出。只有当数据未填满缓冲区时才会进行原先的操作(主要是DMAStop这一步)。到这里,三个中断触发的逻辑总算是理顺了,接下来只需要进行搬运数据的处理就可以了。
usart.c:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void HAL_UART_RxHalfCpltCallback (UART_HandleTypeDef *huart) if (huart->Instance == USART1)1 ; uint8_t txbuf1[] = "rxhalf\n" ;HAL_UART_Transmit (&huart1, txbuf1, sizeof (txbuf1), 0xFFFF );2 - 1 ;for (int i = Rx_buffer_head; i <= Rx_buffer_tail; i++)void HAL_UART_RxCpltCallback (UART_HandleTypeDef *huart) if (huart->Instance == USART1)0 ; uint8_t txbuf2[] = "rxfull\n" ;HAL_UART_Transmit (&huart1, txbuf2, sizeof (txbuf2), 0xFFFF );1 ;1 ;for (int i = Rx_buffer_head; i <= Rx_buffer_tail; i++)
中断服务函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 0 ;if (__HAL_UART_GET_FLAG (&huart1, UART_FLAG_IDLE))__HAL_DMA_GET_COUNTER (&hdma_usart1_rx); __HAL_UART_CLEAR_IDLEFLAG (&huart1); if (temp_size == 0 ) else if (temp_size != 0 ) "rxidle\n" ;sizeof (txbuf3), 0 xFFFF);if (Rx_half_flag == 0 ) 1 ; for (int i = Rx_buffer_head; i <= Rx_buffer_tail; i++)else if (Rx_half_flag != 0 ) 1 ;2 ;for (int i = Rx_buffer_head; i <= Rx_buffer_tail; i++)0 ;0 ;0 ;0 ;
写到这里只处理了单次接收数据大小小于缓冲区长度的情况,可以发现代码量还是挺大的。尤其是这么写代码存在一个比较麻烦的逻辑:当DMA接收的数据量大于缓冲区大小RX_BUFFER_SIZE时,由于DMA工作在循环模式,那么溢出的数据会被DMA重新放到缓冲区的开始部分,从而覆盖原有的数据。要处理这部分数据势必要引入比较复杂的判断机制,还要实时更新队首和队尾的指针,导致整个程序变得比较复杂。
好在HAL库除了普通的HAL_UART_Receive_DMA()和HAL_UART_RxCpltCallback()外,HAL库还提供了HAL_UARTEx_RxEventCallback回调。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 __weak void HAL_UARTEx_RxEventCallback (UART_HandleTypeDef *huart , uint16_t Size )UNUSED (huart );UNUSED (Size );
该回调函数会在“advanced reception service”事件发生后触发,这里的所谓高级接收服务就包括之前需要分开判断的DMA半满中断、DMA满溢中断和空闲中断(实际上还有一个错误中断)。这三个中断触发后都会回调HAL_UARTEx_RxEventCallback()函数。在拷贝数据时,无需再单独进行中断回调类型的判断。由于DMA工作不依赖CPU,因此在该函数内要做的就是将缓冲区内的数据拷贝至目标地址。注意这里的形参Size表示缓冲区可用数据长度(从这个位置开始往后的位置都为空),而不是本次回调所接收的数据长度。
再对照一下这张图,红色的部分就是rx_size,其值等于Size(缓冲区总的有效数据长度)减去rx_buf_head(头指针)。当缓冲区溢出并循环存储新数据至缓冲区开头时,Size会同步更新。
原先的三个中断中的代码可以合到一个中实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void HAL_UARTEx_RxEventCallback (UART_HandleTypeDef *huart, uint16_t Size) uint8_t txbuf[] = "rx done\n" ;HAL_UART_Transmit_IT (&huart1, txbuf, sizeof (txbuf));static uint8_t rx_buf_head = 0 ;static uint8_t rx_size; for (uint16_t i = 0 ; i < rx_size; i++)if (final_index >= RxFinalSize) final_index = 0 ; if (rx_buf_head >= RxBufSize) rx_buf_head = 0 ;
这么写就无需判断到底是哪个中断触发的回调,只需要通过Size和头指针位置计算本次接收到的数据长度,然后按照队列逻辑按次序拷贝即可,因DMA循环而引起的溢出可通过取模操作来处理。
验证:
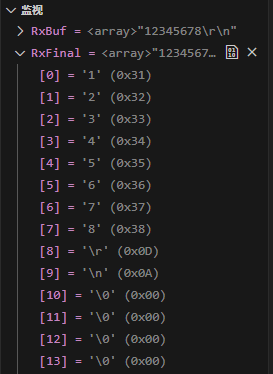
输入“12345678\r\n”:
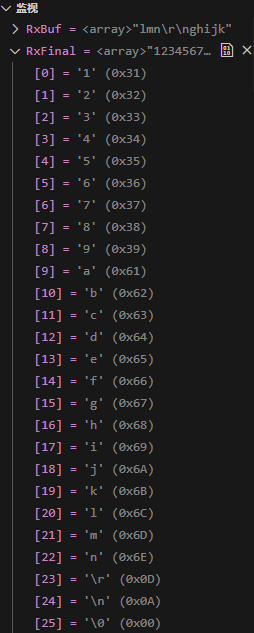
输入“123456789abcdefghijklmn”:
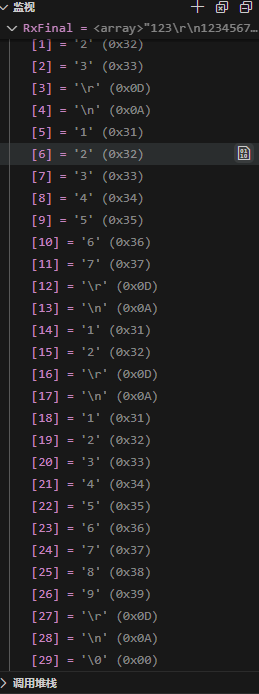
先输入"123",再输入"1234567“,再输入"12",再输入"123456789”:
验证成功。
Github项目地址