机器学习基础
Machine Learning can be divided to :
- supervised learning
- unsupervised learning
Supervised learning
Needs data set with labels
TO: predict unknown future output
-
Classfication Problem (discrete): to predict a discrete output (say yes or no), e.g Cancer benign or malignant diagnosis
-
Regression Problem (Continous): to predict a specific number, e.g Stock Price Prediction
During a linear regression problem we have to solve a minimization problem, to minimize the difference between and .
Regression Problem
Training set + learning algorithm -> generate hypothesis function
takes input (e.g. size of house) and output (e.g. estimated selling price)
Cost Function:
Sigma from 1 to m (m equal to sample size)
Gradient Descent
repeat until convergence:
(for = 0 and = 1)
:= means denote assignment
:learning rate, basically controls how big is a step when descent
and have to be updated simultaneously
Linear Regression Algorithm
TO: Apply gradient descent algorithm to minimize squared error cost function
“Batch” gradient descent: each step of gradient descend uses all training examples
Multiple features (variables)
Hypothesis:
Parameters:
Cost function:
Sigma from i=1 to m
Gradient descent:
repeat fellow:
(simutaneously update for every )
As a result new algorithm will be like fellow:
(simultaneously update for )
E.g from a data set with three features it may like follows:
Feature Scaling & Mean normalization
Idea:make sure features are on a similiar scale.
E.g. = size (0-2000 feet^2) while = number of bedrooms (1-5)
Learning rate
- if is too small: slow convergence
- if is too large: may not decrease on every iteration; may not converge
Make sure gradient descent is working correctly.Final goal is converge the cost function.
Features and Polynomial Regression
E.g. Housing prices prediction
Clearly frontage is the first feature and depth is the second feature
To decide which feature is the most important factor to the housing price, thereafter a polynomial regression can be taken:
this formula can be written as:
In this case, feature scaling is becoming increasingly important to get them comparable.
Classification Problem (Discrete)
Sigmoid Function
Want outputs 0 or 1
Sigmoid Function(Logistic Function):
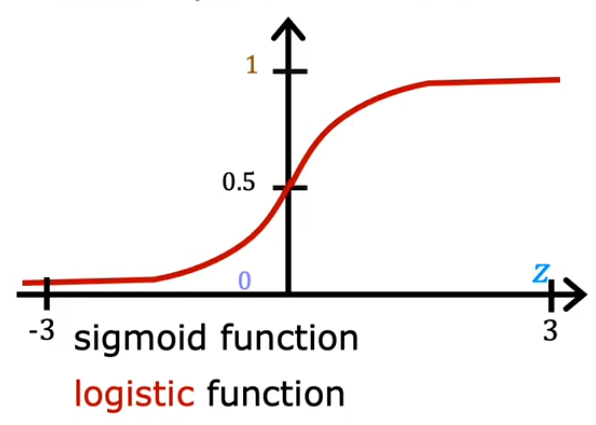
while can be written as vector( is weights and is feature):
Decision Boundary
Clearly the decision boundary is the threshold value of .
is also can be replaced by if there are multiple features.
Clearly the descision boundary is
Cost Funciton
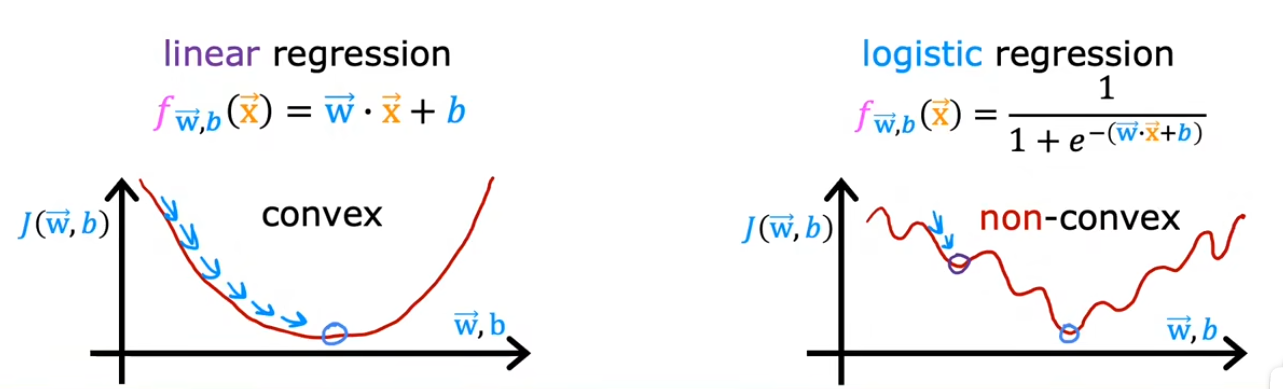
Since MSE under logistic regression is a non-convex function, using MSE as cost function index may get “stuck” at the inflection point of the function, causing error.
Target:create or select a new cost function to make it convex.
The loss function of logistic regression uses the log-likelihood loss function, also known as the cross-entropy loss function, which is used to measure the difference between the model prediction and the true label. The loss function is defined as:
while
- :sample amounts
- : true label (0 or 1) of sample
- : The model predicts the probability of sample , i.e.
The goal of this loss function is to minimize the gap between the predicted and actual labels.
Training Logistic regression
Use gradient descent to minimize the cost function .
we have
and
what we need to do is update them simultaneously.
Unsupervised learning
Needs data set without labels
TO: Automatically discover the internal patterns or structures of data, such as dividing data into different clusters, revealing the inherent laws of data, or simplifying data representation.
Example : Extracting vocals from audio
决策树(Decision Tree)
E.g.:判断动物是否为猫
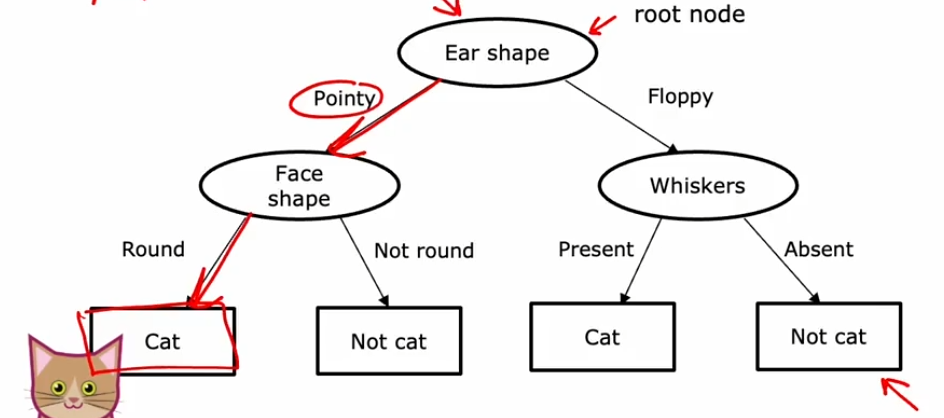
决策树训练步骤
- 确认第一个决策节点(Node)后对样本进行分类 例如:待检测动物的耳朵是圆的还是尖的
- 确认剩下的节点
需要解决的问题
- 如何确定每个节点所用来进行分类的特征(Feature)?如:是根据耳朵类型进行分类还是根据体型进行分类
- 什么时候停止继续分类(split)?
- 某节点能够做到100%的分类时(如有猫DNA的动物一定是猫,不可能是其他)
- 某节点之后决策树溢出
- 继续进行决策所带来的提升低于阈值
- 节点中的样本数量过少